
由于个人时间有限,这部分目前还没有来得及整理,我会在后续慢慢完善,请您谅解。 我暂时列出一个简单的待整理大纲。欢迎 Fork 本项目,和我一起来完善。
算法
💡加油
作为一名前端,在这块可能相对薄弱。在整理这块虽然有些畏惧,但想着既然要做了,那就带着重零学习的心态来面对,祝大家也克服恐惧,早上找到理想的工作。
数据结构
数据结构(data structure)是计算机中存储、组织数据的方式。
数据结构是一种具有一定逻辑关系,在计算机中应用某种存储结构,并且封装了相应操作的数据元素集合。它包含三方面的内容,逻辑关系、存储关系及操作。
不同种类的数据结构适合于不同种类的应用,而部分甚至专门用于特定的作业任务。例如,计算机网络依赖于路由表运作,B 树高度适用于数据库的封装。
算法复杂度
时间复杂度:一个算法执行所耗费的时间。
空间复杂度:运行完一个程序所需内存的大小。
常见的数据结构
栈(Stack)
栈是一种特殊的线性表,它只能在一个表的一个固定端进行数据结点的插入和删除操作。
队列(Queue)
队列和栈类似,也是一种特殊的线性表。和栈不同的是,队列只允许在表的一端进行插入操作,而在另一端进行删除操作。
数组(Array)
数组是一种聚合数据类型,它是将具有相同类型的若干变量有序地组织在一起的集合。
链表(Linked List)
链表是一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。
树(Tree)
树是典型的非线性结构,它是包括,2 个结点的有穷集合 K。
图(Graph)
图是另一种非线性数据结构。在图结构中,数据结点一般称为顶点,而边是顶点的有序偶对。
堆(Heap)
堆是一种特殊的树形数据结构,一般讨论的堆都是二叉堆。
散列表(Hash table)
散列表源自于散列函数(Hash function),其思想是如果在结构中存在关键字和 T 相等的记录,那么必定在 F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。
常用算法
数据结构研究的内容:就是如何按一定的逻辑结构,把数据组织起来,并选择适当的存储表示方法把逻辑结构组织好的数据存储到计算机的存储器里。算法研究的目的是为了更有效的处理数据,提高数据运算效率。数据的运算是定义在数据的逻辑结构上,但运算的具体实现要在存储结构上进行。
一般有以下几种常用运算:
检索
检索就是在数据结构里查找满足一定条件的节点。一般是给定一个某字段的值,找具有该字段值的节点。
插入
往数据结构中增加新的节点。
删除
把指定的结点从数据结构中去掉。
更新
改变指定节点的一个或多个字段的值。
排序
把节点按某种指定的顺序重新排列。例如递增或递减。
十大排序
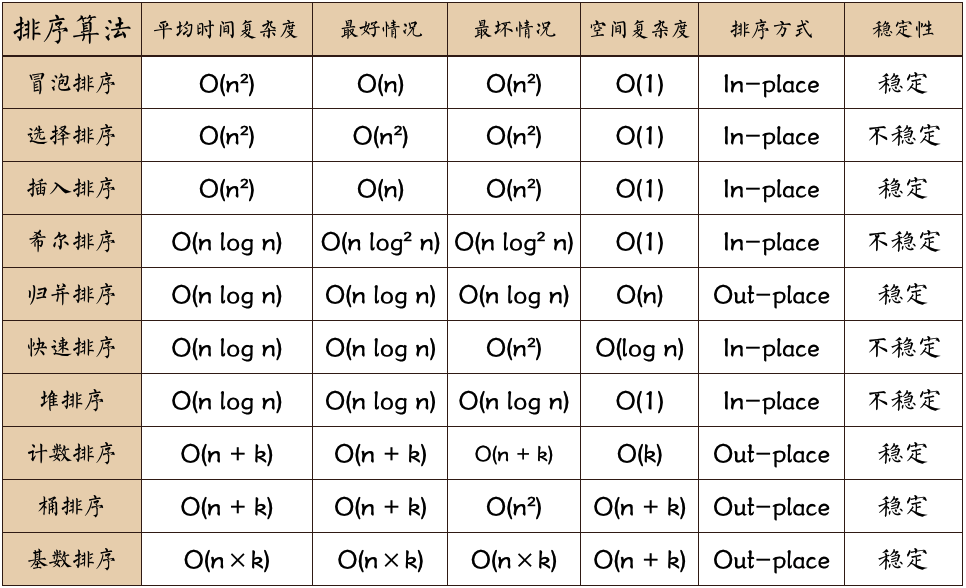
图片名词解释:
- n: 数据规模
- k: “桶”的个数
- In-place: 占用常数内存,不占用额外内存
- Out-place: 占用额外内存
